一、社交电商时代的NLP信息挖掘
小红书笔记数据中蕴含大量信息,但其内容往往较为发散。如果能聚焦到其中与消费决策相关的部分,则可以帮助消费品品牌更了解消费者,提升产品研发和营销的效率。
使用传统的分词统计词频方法很难识别不同信息间的差异。 本文介绍了一种方法,来对小红书中的各类信息进行高效且效果显著的聚类。
二、对比三种分析方案:词频统计、词义聚类和句义聚类
三种方法采用的模型

1. 词频统计
词频统计是最传统的NLP分析方法。在此任务中,其表现不佳,主要因为以下两方面问题:
- 出现次数靠前的词多是无语义的助词或标点
- 由于小红书平台话题高度分散,大量有语义的词出现次数较低
2. 词义聚类
基于词义的聚类基本原理是:
- 将句子拆分成词
- 将词编码,每个编码定义为句子的一个维度(若句子中出现了某词,则在该词的维度记1,反之记0)
- 使用聚类算法计算句子间的相似度,或是使用降维算法将将高维信息映射至二维以便可视化展示。为了方便直观理解,我们选用了后者(降维)的方法
基于词义的聚类存在以下局限性:
- 未考虑词本身的相关性。而如果要做近义词的修正又要涉及大量的人工标注工作
- 词聚类的结果反映出的最显著信息与词频统计的结果高度相似,缺少信息量
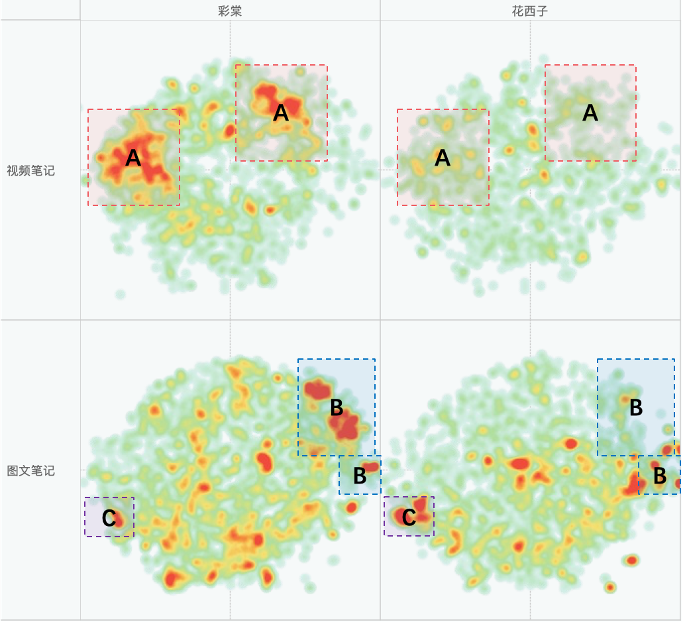
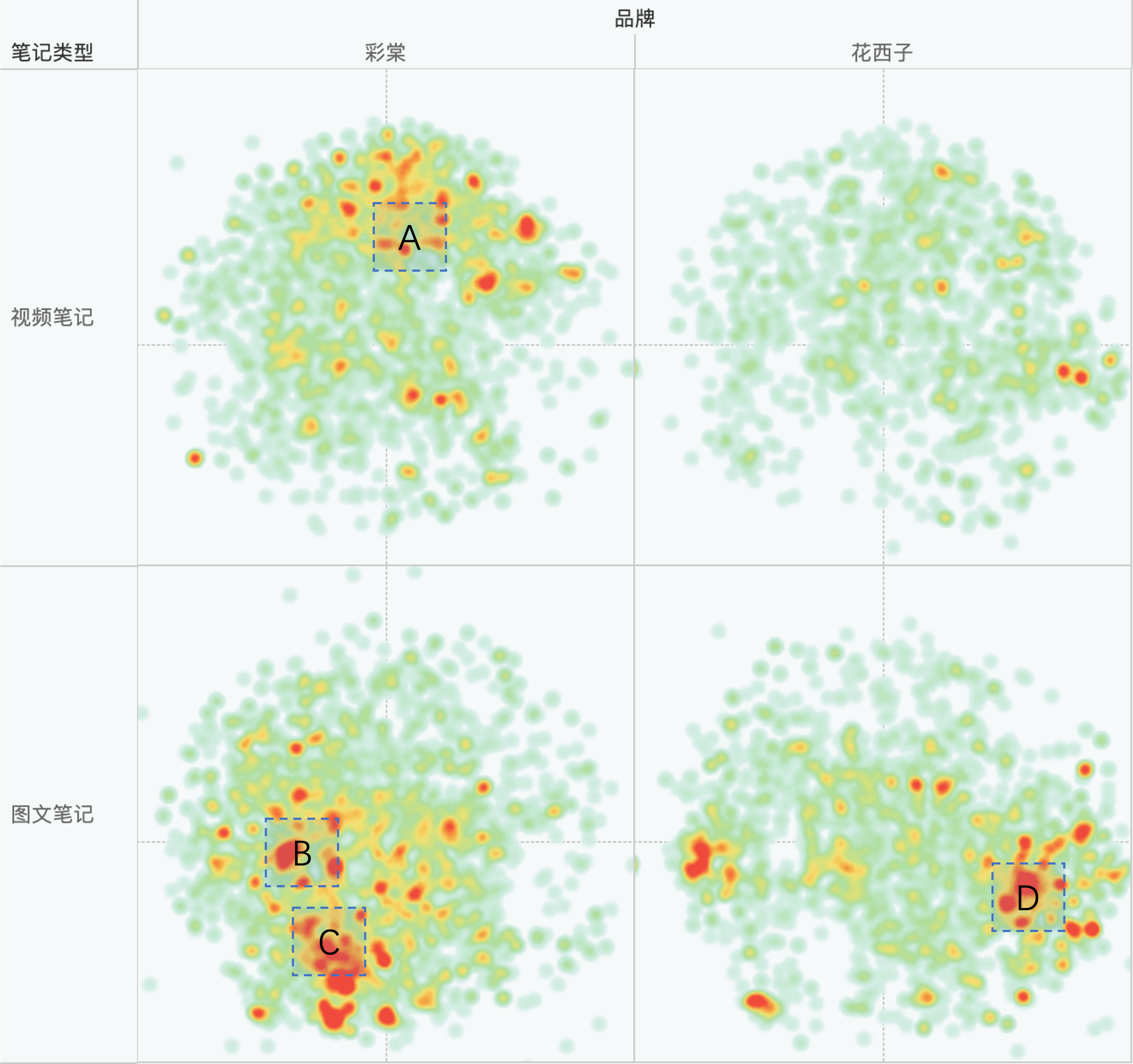
- 词聚类的结果可能会聚焦于词级别的含义,而缺少句级别的理解时词级别的含义借鉴意义较小。比如图中A区域的共性是都提到了“女大学生”,B区域的共性是都提到了“修容”,C区域的共性是都提到了“高光”,D区域的共性是都提到了“花西子”。这些共性对品牌做营销决策的参考价值很低
3. 句义聚类
基于句义聚类的核心思想是采用预训练的NLP模型,结合一定程度的fine-tune来实现对句义的更准确理解。 我们采用了BERT(BERT是GOOGLE实验室在2018年发布的基于注意力机制的NLP模型),在未进行任何fine-tune的情况下,其聚类结果已经相当理想。 其基本原理如下:
- 选取合适的预训练模型
- 这里选取的BERT的输出中的第一位代表句子分类,共有768个维度,每个维度中均可在0~1间取值(相当于BERT的输出会将句子分成最多768个类,每个维度中的值代表句子被分为某类的概率)
- 使用聚类算法计算句子间的相似度,或是使用降维算法将将高维信息映射至二维以便可视化展示。为了方便直观理解,我们选用了后者(降维)的方法
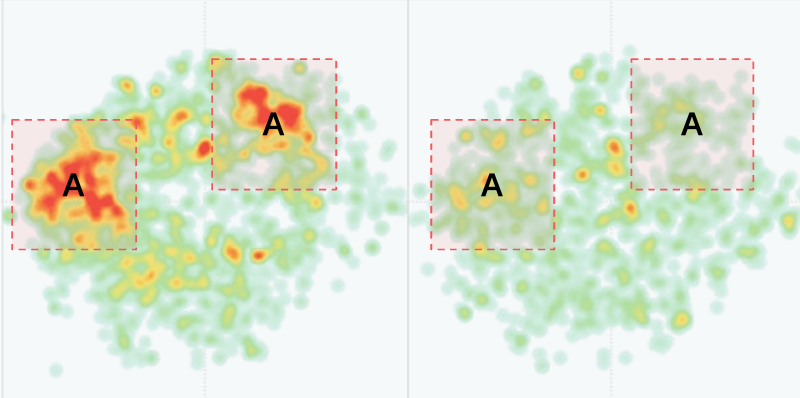
应用此方法,我们发现两个品牌在A、B、C三个区域的笔记数有显著差异。这三个区域分别是: A. 妆容教程类笔记 B. 二手交易类笔记 C. 商业推广类笔记 相较词义聚类的结果,句义聚类对信息的理解更加宏观且更加贴近人类直觉。
三、句义聚类的优化空间
基于上述句义聚类的结果,如果辅以进一步的人工标注,并基于小红书的语料对BERT模型进行fine-tune,预计能取得更加符合预期的结果。