前情提要
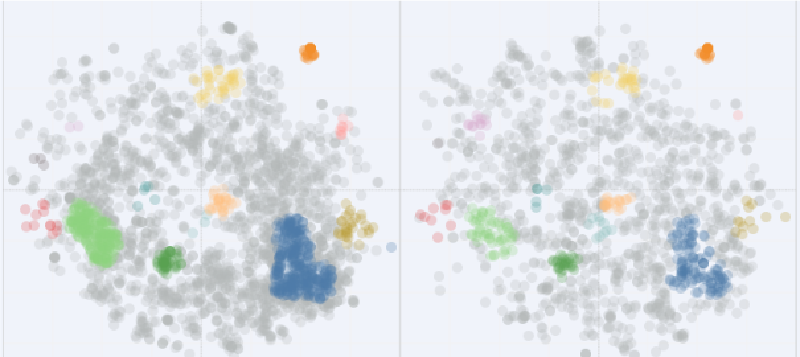
在上一篇关于小红书笔记标题聚类的研究中,我们用BERT输出初步的分类结果,再用T-SNE对分类结果做了降维,最后根据各笔记的分布密度识别出了“妆容教程类”、“二手交易类”和“商业推广类”三类笔记。 显然,最后一步非常依赖人的判断,难以规模化并且不太客观。
基于点密度的聚类算法
本次我们在之前的基础上增加了基于DBSCAN的聚类(DBSCAN是基于点密度的分类算法,通过“同类内的最小距离”(eps)和“最小样本数”(min_samples)来调节聚类效果)。 相较于传统的KMeans算法(通过指定集群数量来调节聚类效果),该算法具有以下优势:
- 无需指定集群数量(很显然我们是无法知道小红书标题中集群的总数的)
- 没有明显集群关系的点会被归至其他类
同时,运用该算法也要克服一个挑战,即如何找到合适的eps及min_samples参数。
参数调优
将轮廓系数作为评价指标
显然,如果eps或min_samples设置的过大,会导致大量的点被分至同一类进而丢失有效信息,反之亦然。 为解决这一问题,我们首先引入“轮廓系数”作为算法的评价指标,测试不同参数下的“轮廓系数”大小。理想情况下,“轮廓系数”越大越好(说明分类界限越分明)。然而,在上述任务中,轮廓系数大可能引起两方面的负面影响:
- 分类总数变少
- “其他”类中的样本数变多
引入“其他类样本占比”和“分类总数”来优化评价指标
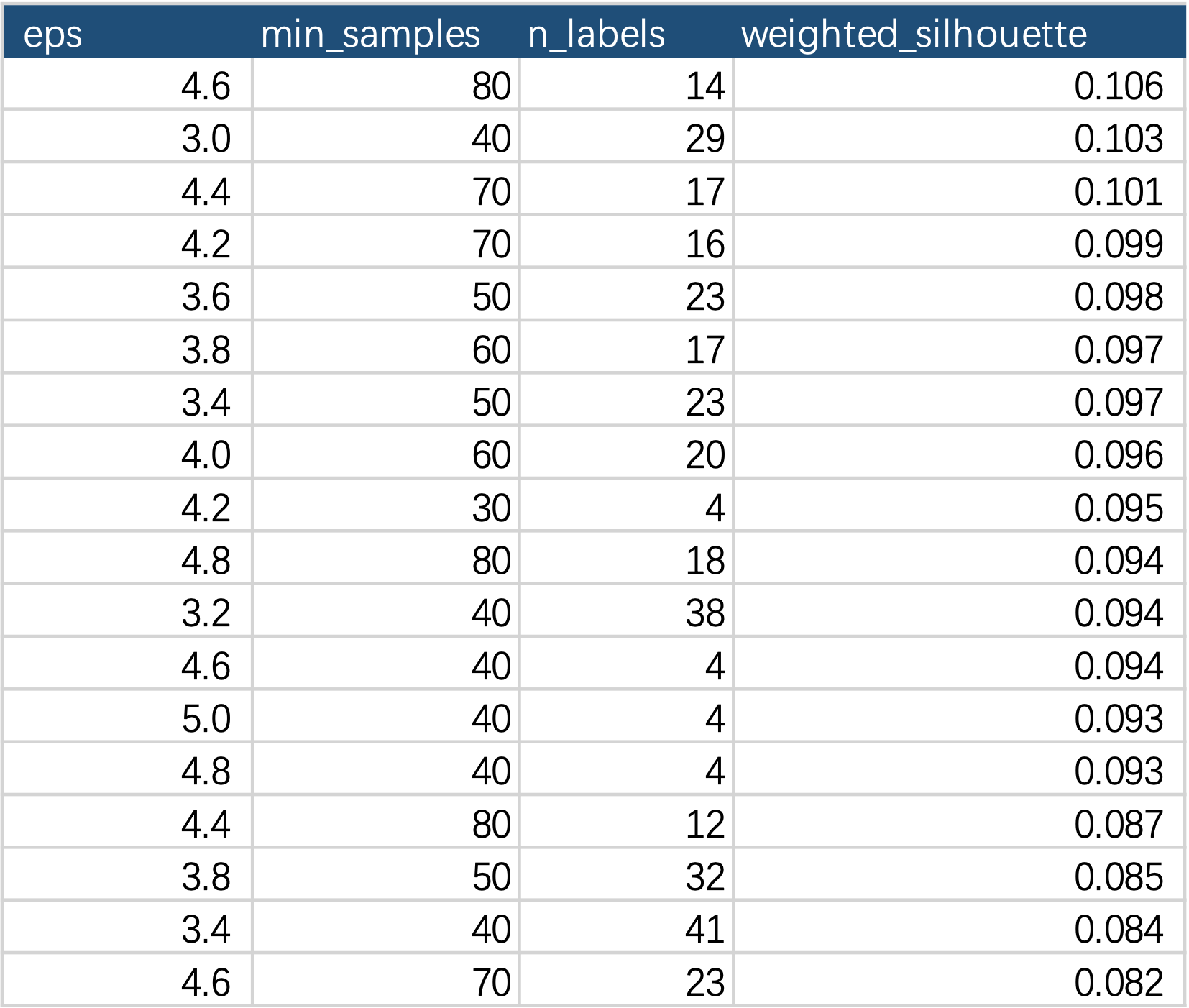
为克服上述负面影响,我们引入了“其他类样本占比”,用此指标与轮廓系数求调和平均作为聚类评分值(越大越好)。同时我们计算了不同参数下的分类总数。下表展示了部分参数下的聚类评分值(weighted_silhouette)。
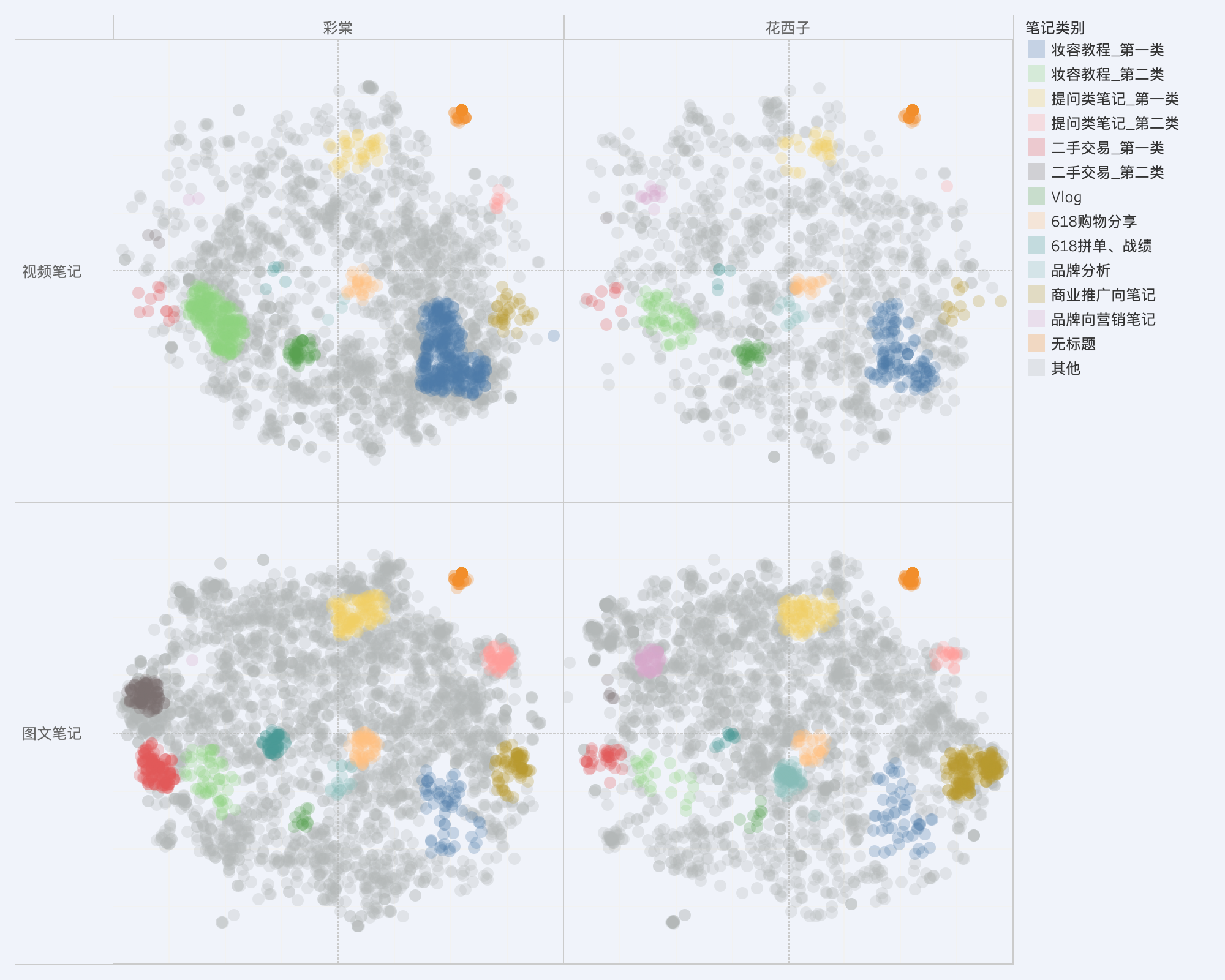
 我们最终选取的是n_labels大于10中weighted_silhouette最大的方案。最终聚类效果如下图。可见,我们不仅清晰区分出了此前方案已识别出的“妆容教程类”、“二手交易类”和“商业推广类”三类笔记,还额外识别出了额外的7类笔记。
我们最终选取的是n_labels大于10中weighted_silhouette最大的方案。最终聚类效果如下图。可见,我们不仅清晰区分出了此前方案已识别出的“妆容教程类”、“二手交易类”和“商业推广类”三类笔记,还额外识别出了额外的7类笔记。
附录
轮廓系数
轮廓系数是一种用于评估聚类质量的指标,旨在衡量聚类结果中样本的紧密度和分离度。它可以帮助我们了解聚类算法对数据的划分效果如何,即样本是否被正确地分为相似的簇并且不同的簇之间有明显的区别。
具体来说,对于每个样本,轮廓系数考虑了两个因素:
-
样本与同一簇中其他样本的相似程度:衡量了样本与其簇内其他样本之间的平均距离。这个值越小,说明样本在其所属的簇内越紧密,聚类效果越好。
-
样本与最近邻不同簇中样本的相似程度:衡量了样本与其最近邻的其他簇之间的平均距离。这个值越大,说明样本与其它簇的样本之间的距离越远,聚类效果越好。
综合考虑这两个因素,轮廓系数的取值范围在[-1, 1]之间:
- 一个较高的正值表示样本与其簇内样本更接近,同时与其他簇的样本距离较远,表示聚类效果较好。
- 一个接近于零的值表示样本与其簇内样本的距离近似于与其他簇的样本距离,聚类效果不明确。
- 一个负值表示样本更接近于其它簇的样本,聚类效果不好。
因此,轮廓系数越接近于1,聚类效果越好,越接近于-1或小于0,聚类效果越差。在使用轮廓系数时,我们希望找到最高的轮廓系数,以获得最优的聚类结果。
在Tableau Public查看可交互的数据
https://public.tableau.com/app/profile/t.s1480/viz/_16905304270770/sheet0