I. NLP Information Mining in the Era of Social E-commerce
Xiaohongshu (Little Red Book) note data contains a wealth of information, but its content often tends to be divergent. If we can focus on the part related to consumer decision-making, it can help consumer goods brands better understand consumers and improve product development and marketing efficiency.
Using traditional word segmentation and frequency statistics, it is challenging to identify differences between various pieces of information. This article introduces an efficient and effective method to cluster different types of information in Xiaohongshu effectively.
II. Comparing Three Analysis Approaches: Word Frequency Statistics, Semantic Clustering, and Sentence Semantic Clustering
Models Used by the Three Approaches

1. Word Frequency Statistics
Word frequency statistics are the most traditional method in NLP analysis. In this task, it performs poorly primarily due to two issues:
- The most frequent words are often semantically meaningless particles or punctuation marks.
- Due to the highly scattered nature of topics on Xiaohongshu, many semantically meaningful words have low frequencies.

2. Semantic Clustering
The basic principle of semantic clustering is as follows:
- Split sentences into words.
- Encode words, defining each encoding as a dimension of the sentence (if a word appears in the sentence, mark it as 1; otherwise, mark it as 0).
- Use clustering algorithms to calculate the similarity between sentences or use dimension reduction algorithms to map high-dimensional information to two dimensions for visualization. For intuitive understanding, we chose the latter method (dimension reduction).
Semantic clustering based on word meanings has the following limitations:
- It does not consider the relevance of words themselves. To address this, a significant amount of manual annotation work is required for synonym correction.
- The results of word clustering largely reflect the same information as word frequency statistics, lacking information richness.
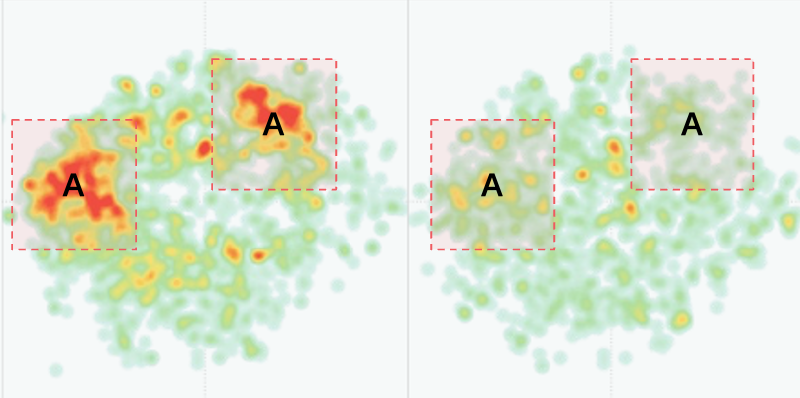
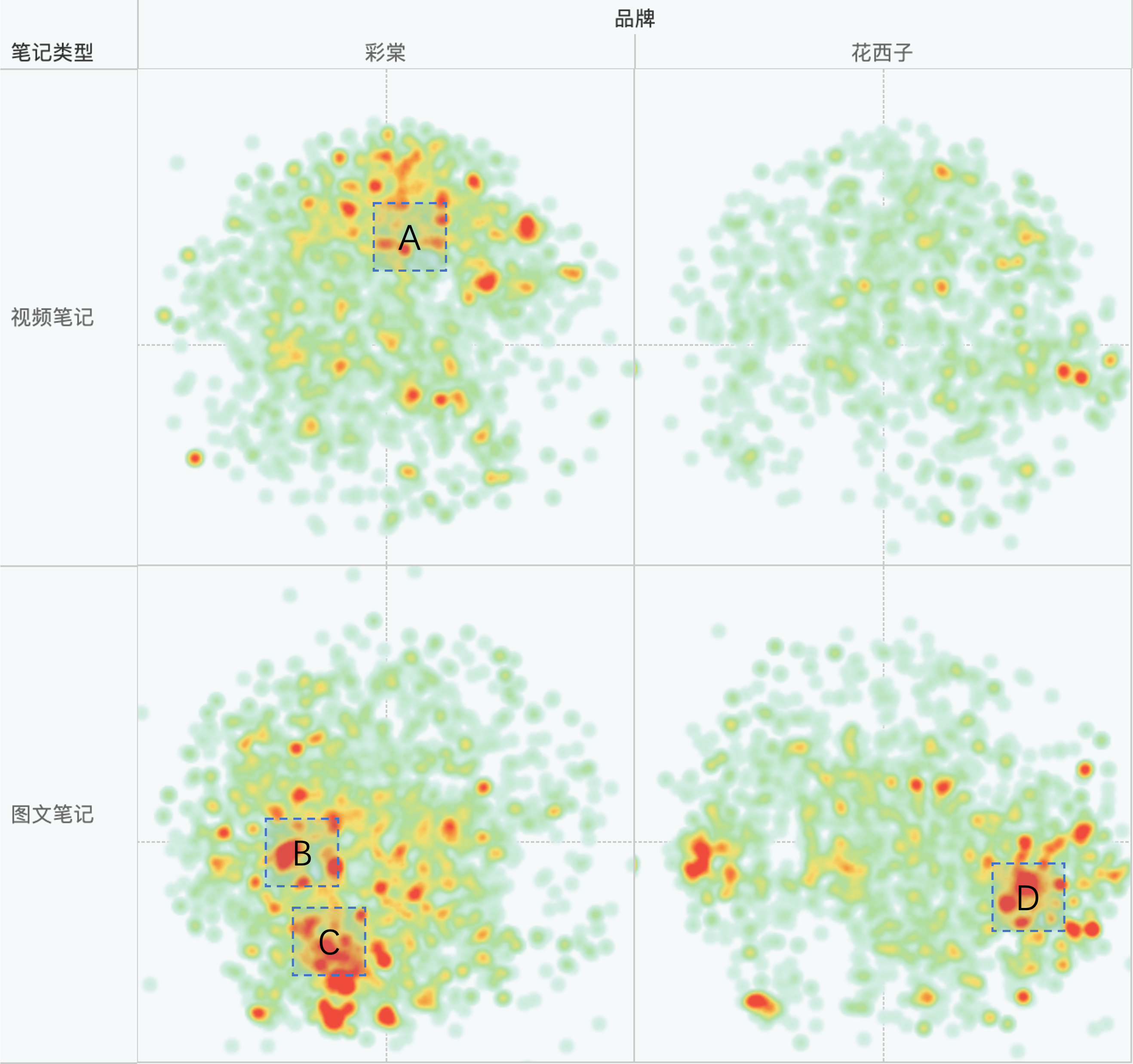
- The results of word clustering may focus on word-level meanings and lack sentence-level understanding, which limits its usefulness. For example, Area A in the chart focuses on mentioning “female college students,” Area B on “contouring,” Area C on “highlighting,” and Area D on “Huaxizi.” These commonalities have limited marketing decision-making value for brands.
3. Sentence Semantic Clustering
The core idea behind sentence semantic clustering is to use pre-trained NLP models, combined with some degree of fine-tuning, to achieve more accurate understanding of semantics. We used BERT (BERT is a pre-trained NLP model based on attention mechanisms released by Google Labs in 2018). Even without any fine-tuning, its clustering results are quite satisfactory.
The basic principle is as follows:
- Choose an appropriate pre-trained model.
- In this case, we selected BERT’s output, where the first dimension represents sentence classification, with a total of 768 dimensions. Each dimension can take values between 0 and 1 (corresponding to BERT’s output classifying sentences into a maximum of 768 classes, with each dimension’s value representing the probability of the sentence being assigned to a certain class).
- Use clustering algorithms to calculate the similarity between sentences or use dimension reduction algorithms to map high-dimensional information to two dimensions for visualization. For intuitive understanding, we chose the latter method (dimension reduction).
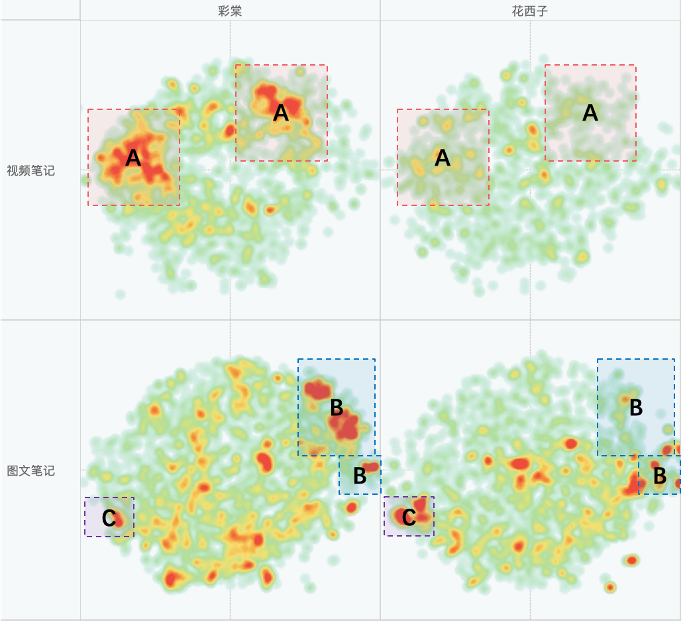
Applying this method, we found significant differences in the number of notes for two brands in three regions: A, B, and C. These three areas are: A. Makeup tutorial notes B. Second-hand trade notes C. Commercial promotion notes Compared to the results of semantic clustering, sentence semantic clustering provides a more macroscopic and human-intuitive understanding of information.
III. Optimization Space for Sentence Semantic Clustering
Based on the results of sentence semantic clustering, further manual annotation and fine-tuning of the BERT model based on Xiaohongshu’s corpus are expected to yield more desired results.